vtt.bzh - Conception d'une web-app NodeJS/VueJS
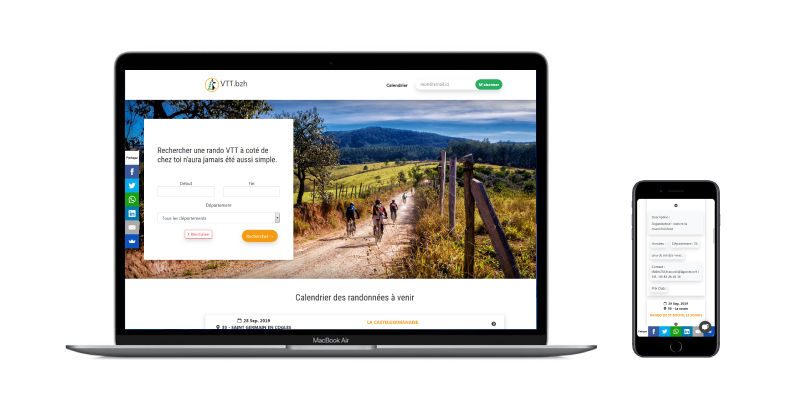
Side Project, 2019 - Site applicatif - vtt.bzh
Créé en 2013, vtt.bzh a connu jusqu'à 10.000 visiteurs /mois. Le MVP que j'avais créé sous Wordpress était très "do things that don't scale". Je réalisais manuellement une curation des randonnées régionnales, que je listais manuelement sur le site. En 2016, je faisais mes premières armes en javascript et développais un premier scraper en NodeJS, lent, très lent ... Le scraper mettait à jour un fichier JSON que je mettais a jour manuelement sur le site. L'objectif était donc d'avoir un scraper plus rapide en back-end et de pouvoir mieux gérer le moteur de recherche en front-end.
Scope et contraintes
Vtt.bzh étant un side project, j’ai l’ownership de l’UX/UI et de l’ensemble de la stack technique.
J’ai également un temps limité.
Je dois donc garder les choses simples à construire et à maintenir.
Comment optimiser le scraper et maximiser l’usabilité du moteur de recherche ?
Réécrire le scraper NodeJS.
Le scraper NodeJS utilisait la librairie de test end-to-end “NightmareJS” un navigateur web haut niveau d’automatisation. Il charge tout le contenu de la page et toutes ses fonctionnalités.
De fait, comme le scraper attendait d’avoir une page chargée à 100% pour commencer son travail (env. 8s /page) il parcourait une centaine de pages en une quinzaines de minutes.
Je choisis donc de challenger cette librairie.
Utiliser le framework front-end VueJS
A a suite d’une longue veilles sur les frameworks front-end, incluant: VueJS, ReactJS et Angular. C’est séduit par le design de VueJS que je choisi donc de migrer mon POC du javascript natif à une SPA (Single Page Application) VUE. (une version non officelle a été également développée en AngularJS).
Le résultat est sans appel, une application fluide, une navigation intuitive et un code maintenable grace à une architecture en composant.
Passage de l’API a un FAAS AWS lambda
Après avoir utlisé, un temps, la librairie scrapy, reconnu pour sa performance et son coté clef en main dans le domaine, et écrit une version du scrapper en Python, je m’amuse a le réécrire en rust.
Mais toujours attiré dans ma veille par la JAM stack, je me disait qu’un cron etait le cas d’usage type d’un FAAS et avec juste un endpoint pour l’API basculer sur AWS lambda coté back faisait sens.
C’est donc une nouvelle version en NodeJS avec un scrapper home-made et 100% automatisé qui voit le jour.
Une app plus simple et plus rapide
Coté back, le gain est de temps de traitement du scraper est probant, il est désormais de 1 à 2 minutes.
Coté front, la refonte en VueJS du moteur de recherche a permis un meilleur découpage de l’app et une plus grande evolutivité.